| intrusion | dreams | flash | upset | physior | avoidth | avoidact | amnesia | lossint | distant | numb | future | sleep | anger | concen | hyper | startle |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 2 | 2 | 2 | 3 | 2 | 3 | 2 | 3 | 2 | 2 | 1 | 3 | 4 | 3 | 4 | 2 |
| 2 | 2 | 2 | 3 | 3 | 3 | 3 | 2 | 3 | 3 | 2 | 2 | 3 | 3 | 2 | 3 | 3 |
| 2 | 4 | 4 | 4 | 3 | 3 | 3 | 5 | 4 | 3 | 2 | 3 | 4 | 4 | 4 | 3 | 4 |
| 2 | 1 | 2 | 2 | 1 | 1 | 2 | 2 | 2 | 1 | 1 | 2 | 2 | 1 | 2 | 3 | 3 |
| 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 3 | 2 | 2 | 2 | 3 | 2 | 3 | 2 | 3 |
| 4 | 3 | 2 | 2 | 2 | 2 | 3 | 3 | 2 | 2 | 2 | 3 | 2 | 3 | 2 | 3 | 2 |
MDS in Action
Recent Developments and Implementation
2023-12-06
Example
We start with computing a correlation matrix, subsequently converted into a dissimilarity matrix and fed into smacof’s mds() function, fitting a 2D solution:
Call:
mds(delta = delta, type = "ordinal")
Model: Symmetric SMACOF
Number of objects: 17
Stress-1 value: 0.145
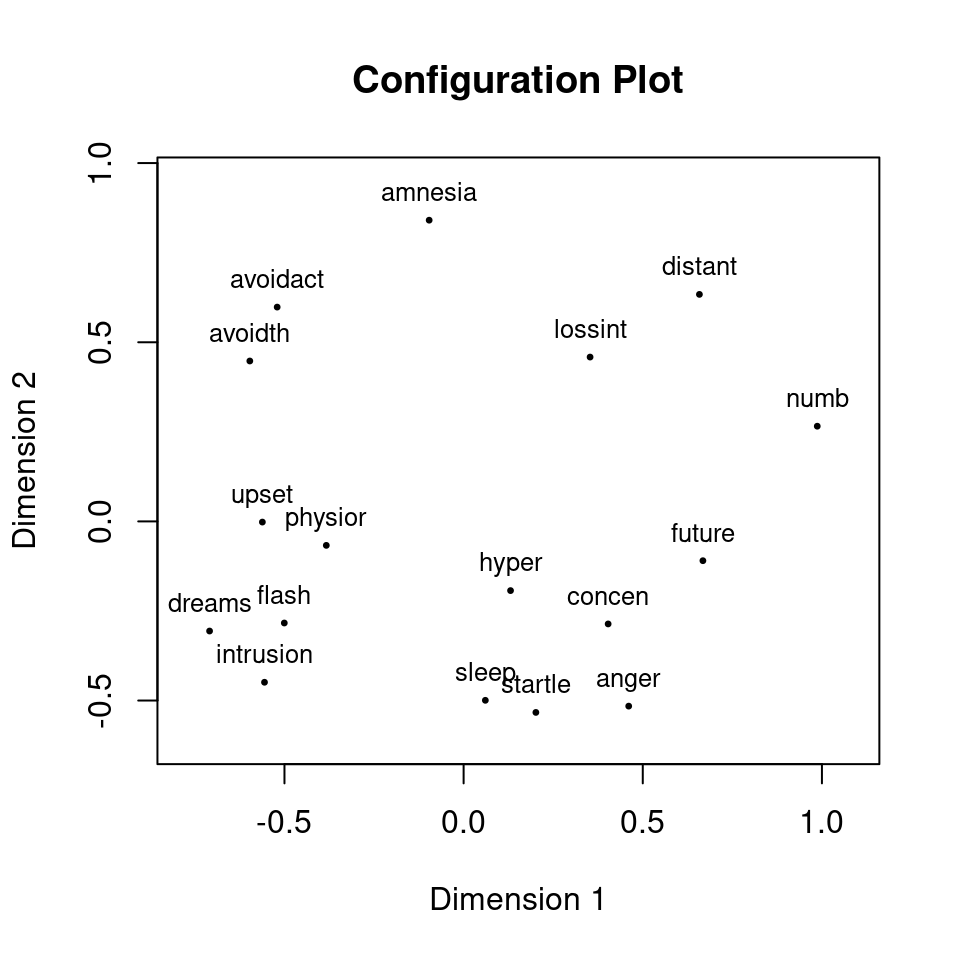
Number of iterations: 22 We get a normalized stress value of 0.145 indicating how well the solution fits. Then we plot the configuration showing how the PTSD symptoms are related to each other (i.e., we create a map of the objects).
Stability of a Solution
For derived dissimilarity setups, one can use a jackknife or a bootstrap to assess the stability of a solution, leading to confidence ellipses around the points in the configuration.
set.seed(123)
boot_wen <- bootmds(fit_mds, data = Wenchuan,
method.dat = "pearson", nrep = 500)
boot_wen
Call: bootmds.smacofB(object = fit_mds, data = Wenchuan, method.dat = "pearson",
nrep = 500)
SMACOF Bootstrap:
Number of objects: 17
Number of replications: 500
Mean bootstrap stress: 0.1607
Stress percentile CI:
2.5% 97.5%
0.1291 0.1982
Stability coefficient: 0.9047 Other parametric approaches:
- Pseudo confidence ellipses based on second stress derivations (de Leeuw, 2019);
- Log-normal framework with ML estimation (Ramsay, 1982), see
smacofxpackage. - Bayesian MDS (Oh & Raftery, 2001), see
bayMDSpackage.

Goodness-of-Fit Assessment
Various transformation functions applied to the Wenchuan data. Shepard plots:
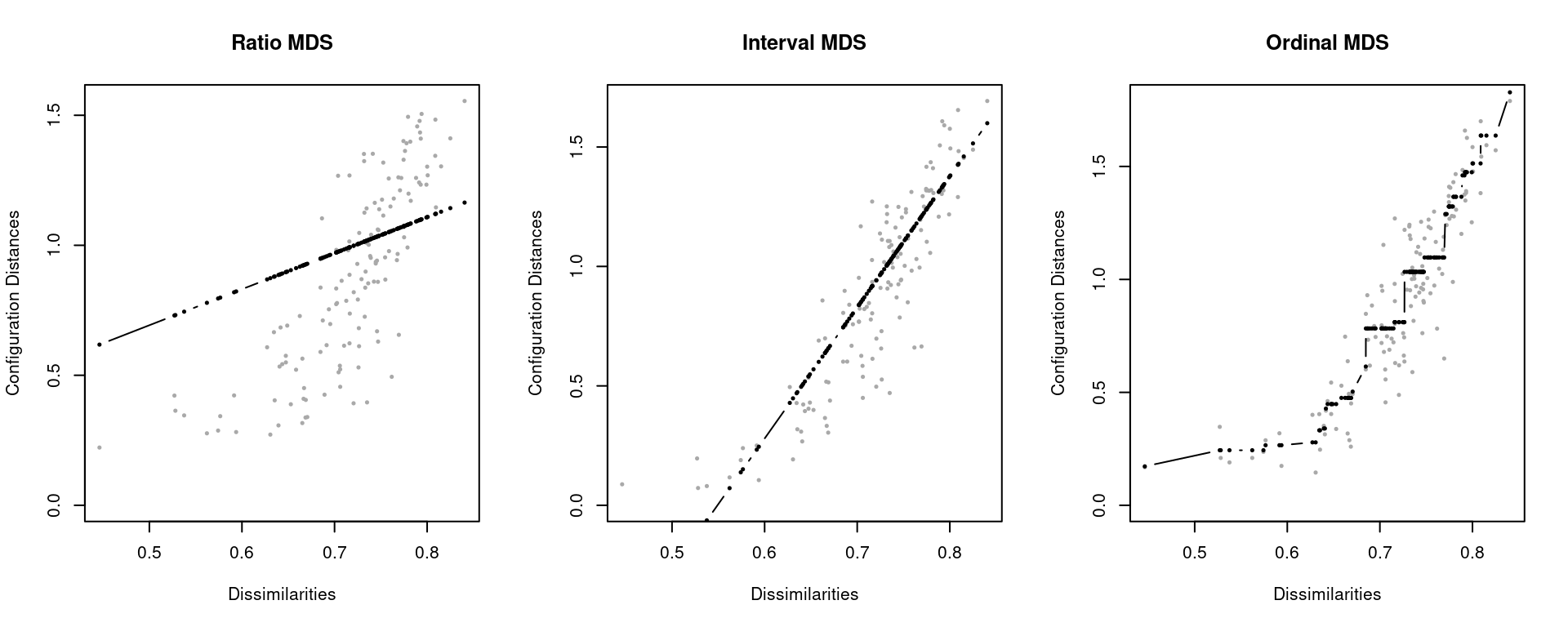
The choice of the transformation function can be made in a data-driven way (Shepard plots), or ad hoc depending on the nature of the input data.
It holds that ordinal stress \(\leq\) interval stress \(\leq\) ratio stress.
Goodness-of-Fit Assessment
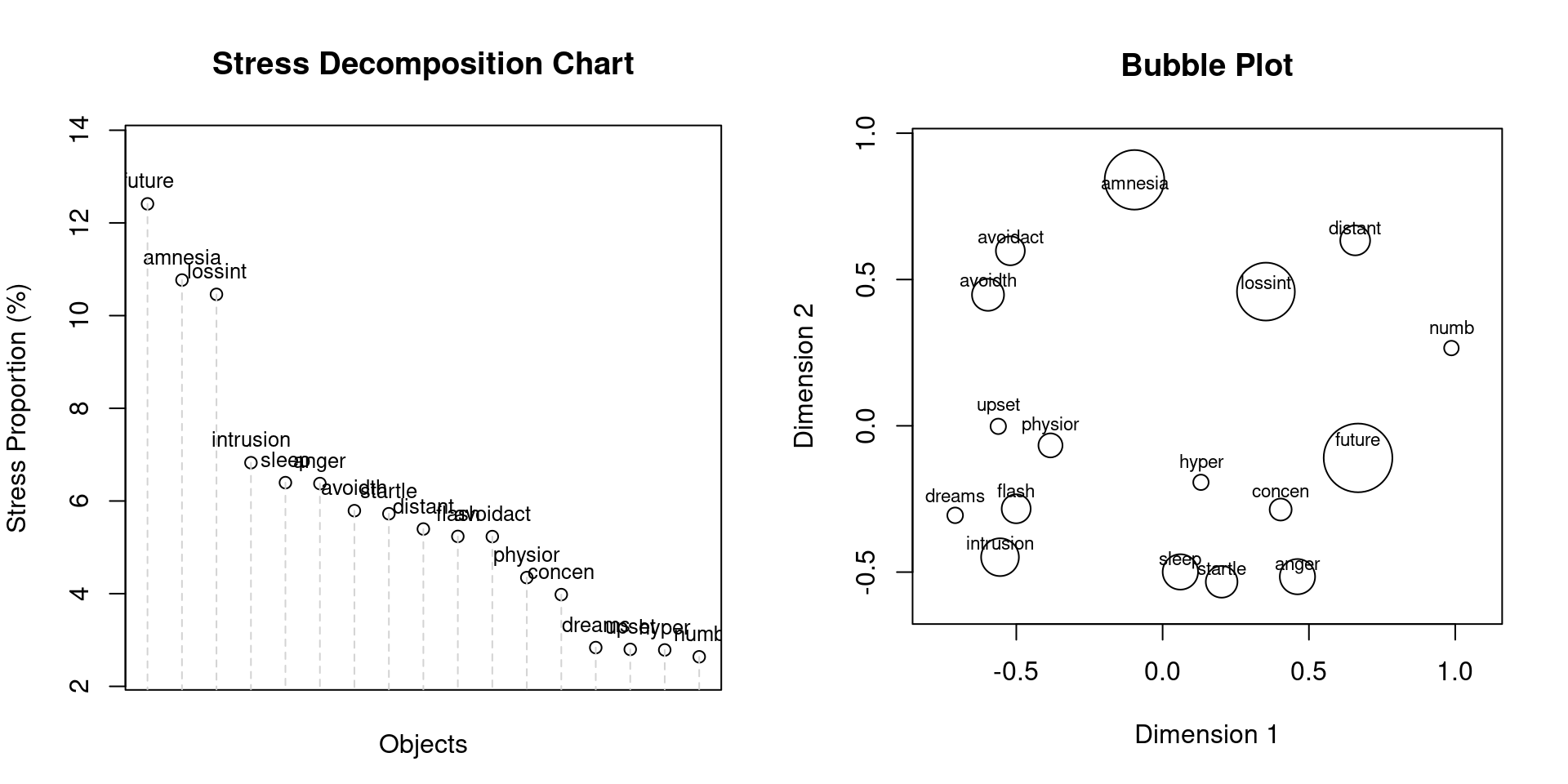
SPP plots: SPP decomposition in percentages, and incorporating the SPP information into the configuration plot (the larger the circle, the larger the SPP):
Interpretation I
As opposed to PCA, there’s usually less focus on interpreting the dimensions in the configuration plot since the solution can be rotated arbitrarily1.
Interpretation options:
- Distances between objects in the configuration plot (most common interpretation).
- Clustering points in the configuration (e.g., a hierarchical cluster analysis on the fitted distance matrix).
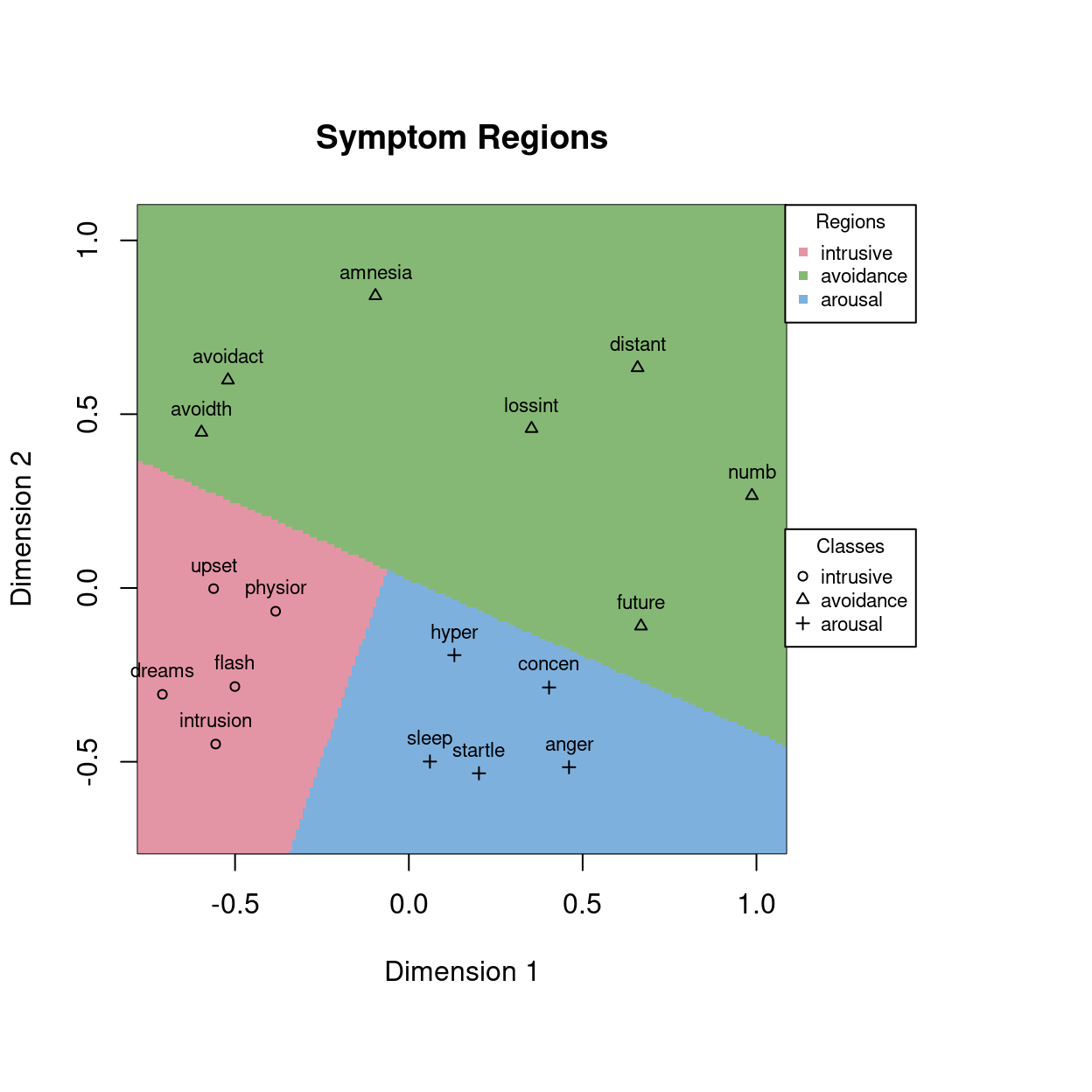
- Partitioning the MDS space using SVM in case we have labels for the objects2. The plot to the right shows a linear SVM-based facet partitioning using the DSM-IV labels.
Interpretation II
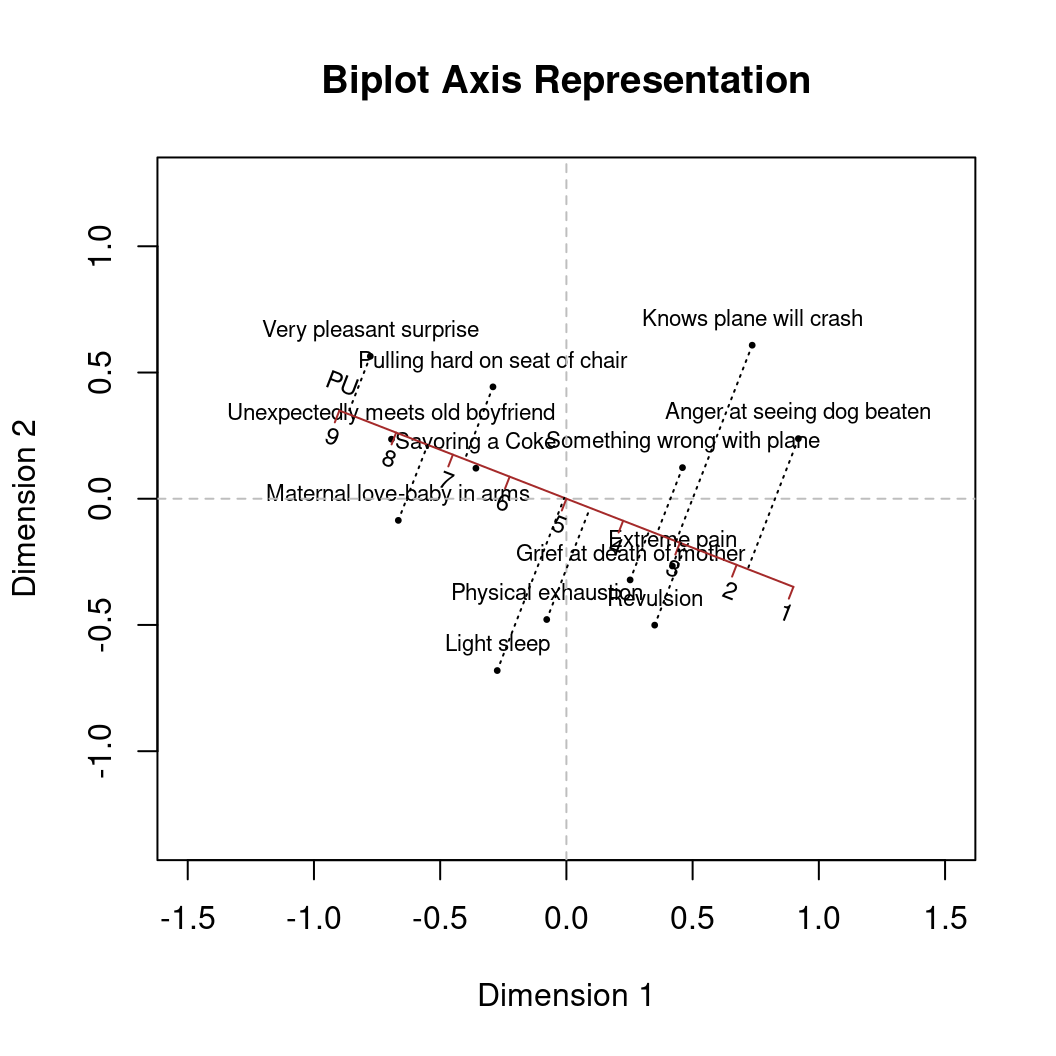
Having object covariates, we can map corresponding axes onto the configuration (either as vector or as actual axes with projections for which the calibrate package comes in handy). This is called an MDS biplot1,2.
MDS biplots solve the multivariate regression problem
\[\mathbf Y = \mathbf{XB} + \mathbf E\]
with \(\mathbf Y\) as an \(n \times q\) of external covariates, and \(\mathbf X\) the MDS configuration. The resulting \(\hat{\mathbf B}\) determines the new axes.
Example:
- Participants had to rate proximities of 13 facial expressions (directly observed proximities).
- Rating scale values were collected for a “pleasant-unpleasant” (PU) covariate.
Procrustes
Let us assume we have two MDS configurations with the same objects but coming from two different conditions. The two resulting configurations may be aligned quite differently due to the “arbitrariness” of the dimensional alignment. This is where Procrustes1 (“the stretcher who hammers out the metal”) comes in.

The goal of Procrustes is to align a testee configuration with a target configuration by removing “meaningless” differences (i.e., translation, rotation, and dilation which don’t change the stress value of a solution).
Procrustes Example
We have two dissimilarity matrices of work values from former West and East Germany. We start with fitting two separate MDS solutions, subsequently aligned with Procrustes (with East Germany as target configuration).
fit_east <- mds(eastD, type = "ordinal")
fit_west <- mds(westD, type = "ordinal")
fit_proc <- Procrustes(X = fit_east$conf, Y = fit_west$conf)
fit_proc
Call: Procrustes(X = fit_east$conf, Y = fit_west$conf)
Congruence coefficient: 0.951
Alienation coefficient: 0.308
Correlation coefficient: 0.666
Rotation matrix:
D1 D2
D1 -0.990 -0.139
D2 0.139 -0.990
Translation vector: 0 0
Dilation factor: 0.672 Work useful for society Work that is meaningful and sensible
0.005 0.072
Interesting work Good chances for advancement
0.199 0.250
Work that requires much responsibility Work where one can help others
0.260 0.265
Independent work Work that is recognized and respected
0.273 0.332
High income Healthy working conditions
0.354 0.372 
Example
Let us fit an ordinal unfolding solution on the car preference data:
Call: unfolding(delta = carconf1, type = "ordinal")
Model: Rectangular smacof
Number of subjects: 100
Number of objects: 6
Transformation: ordinalp
Conditionality: matrix
Stress-1 value: 0.297371
Penalized Stress: 2.330348
Number of iterations: 135 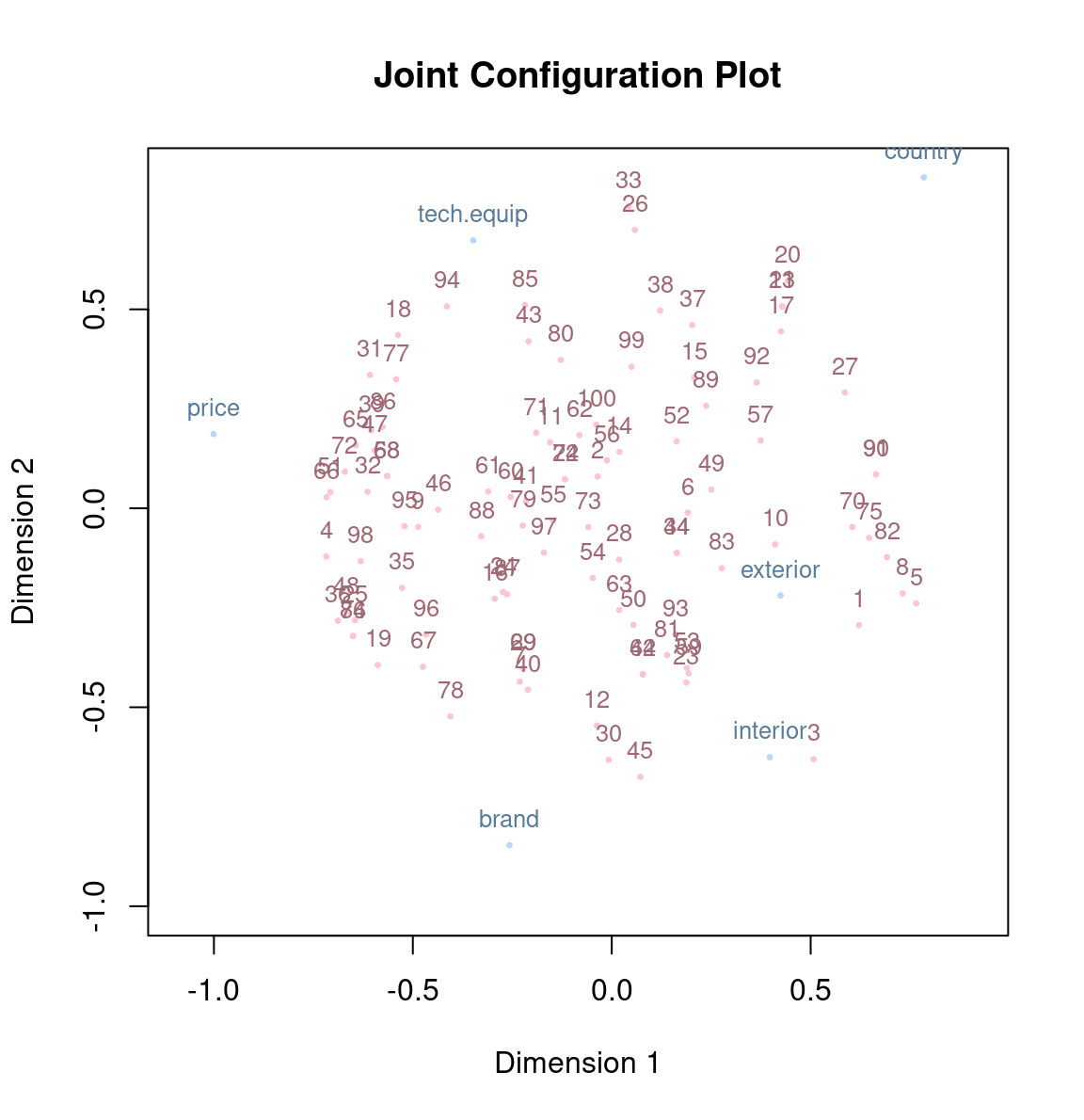
Row-Conditional Unfolding
The Shepard plot shows nicely the difference between an unconditional and a row-conditional solution:
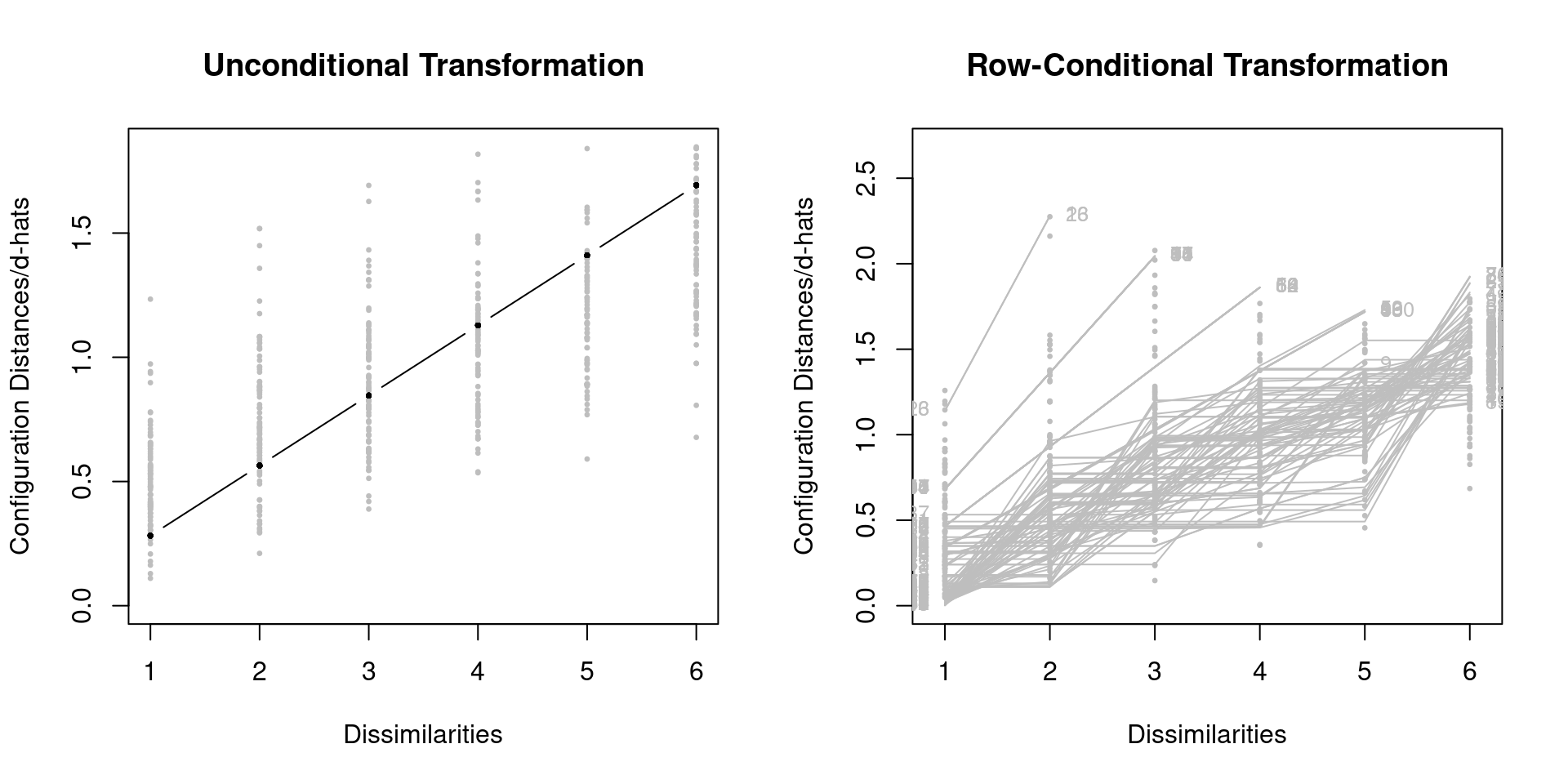
Row-Conditional Unfolding
We get a stress-1 value of 0.297 for the unconditional solution, and 0.203 for the row-conditional one. Let’s look at the configurations:
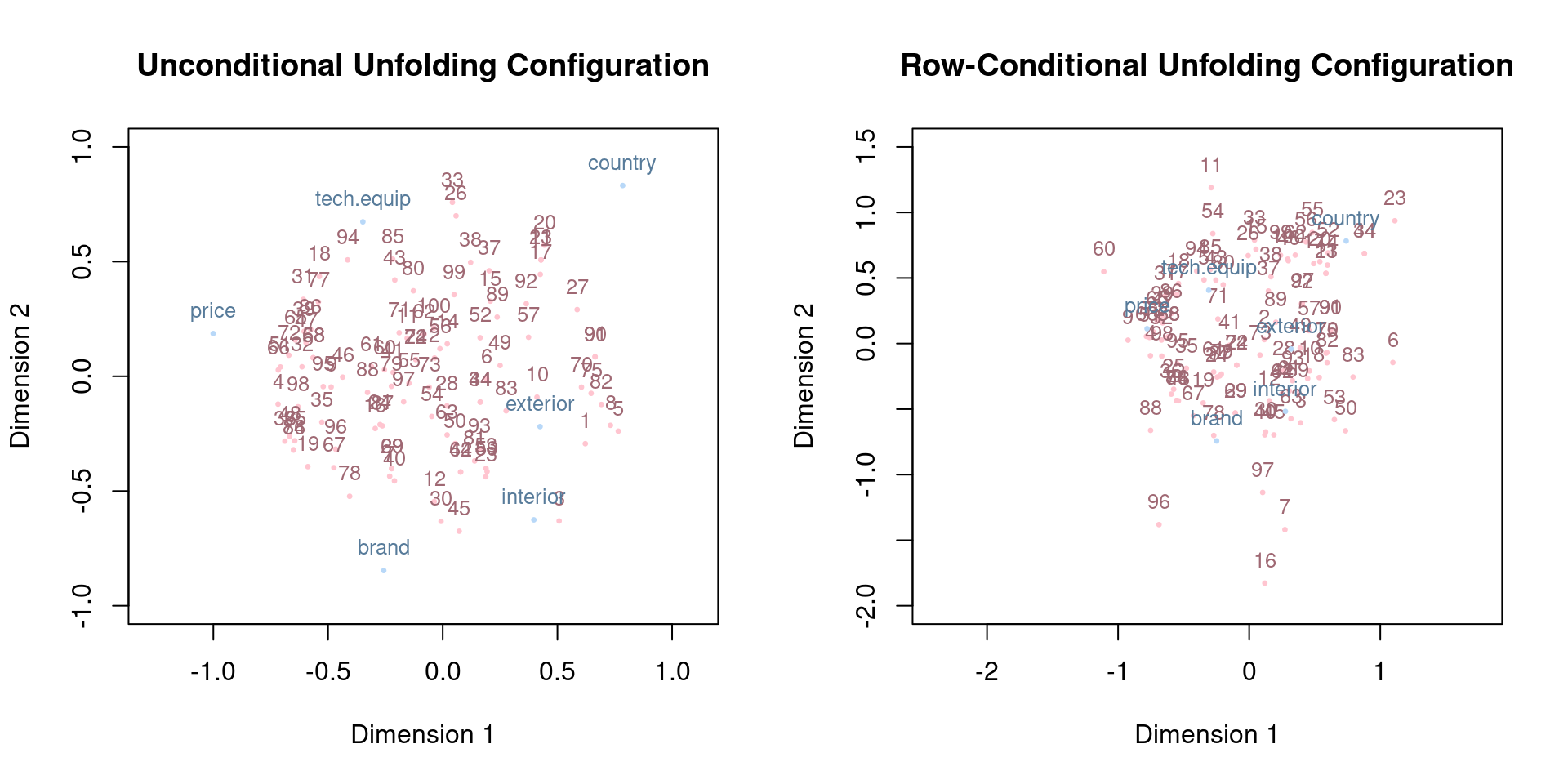
Summary
Takeaways: MDS is a widely applicable family of methods for scaling input dissimilarities, that is, we create a “map” of our data. We have focused on
- basic MDS on a symmetric input dissimilarity matrix (stability, goodness-of-fit assessment, interpretation of a solution) and Procrustes for aligning two or more configurations;
- unfolding on a rectangular input dissimilarity matrix (rankings, ratings) including row-conditionality.
Further details, applications, and related methods can be found in
Mair, P., Groenen, P. J. F., and De Leeuw, J. (2022). More on multidimensional scaling in R: smacof version 2. Journal of Statistical Software, 102(10), 1-47. DOI: 10.18637/jss.v102.i10
Mair, P. (2018). Modern Psychometrics with R. New York: Springer.
